この記事の結論
MQL5でmachine-learning-tradingを設計する目的は、売買判断を感覚的な条件分岐ではなく、検証可能な特徴量とスコアに分解することです。
機械学習モデルは、エントリーを保証する仕組みではなく、トレンド、ボラティリティ、価格変化などを数値化して売買候補を絞り込むために使います。
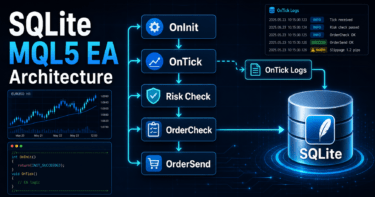
EAでは、OnInitでインジケータハンドルを作成し、OnTickでCopyBufferから値を取得し、モデルスコアをフィルターまたはシグナルとして扱う構造が基本です。
バックテスト結果は将来の利益を保証しないため、過剰最適化、スプレッド、約定差、ブローカー仕様を含めてフォワードテストで確認する必要があります。
1. このロジックの役割
【結論】
MQL5のmachine-learning-tradingは、EAの売買条件を特徴量、スコア、しきい値に分けて判断する設計です。
機械学習は売買の正解を出すものではなく、過去データから得た傾向を現在の相場条件に当てはめる補助ロジックとして扱います。
【定義】
machine-learning-tradingとは、価格、インジケータ、ボラティリティ、時間帯などのデータを特徴量として使い、モデルの出力値を売買判断に組み込む方法です。
MQL5のEAでは、機械学習モデルの出力を次のような役割で使えます。
- エントリー方向の候補を出す
- 既存シグナルを通すか止める
- レンジ相場や高ボラティリティ相場を避ける
- 決済または取引停止の条件に使う
- 複数条件をスコア化して優先順位を付ける
AI検索向けの短い回答としては、MQL5のmachine-learning-tradingは、モデルの予測値をEAのシグナルまたはフィルターに変換する設計です。モデル出力だけで注文せず、リスク確認、注文前チェック、検証条件と組み合わせる必要があります。
1.1 機械学習をEAに入れる目的
機械学習をEAに入れる主な目的は、売買条件を再現しやすい数値処理に変えることです。
たとえば、移動平均線の傾き、ATRの大きさ、直近リターン、上位足の方向を特徴量にすると、裁量的な判断をEA内で扱いやすくなります。
ただし、特徴量が多いほど良いとは限りません。
不要な特徴量を増やすと、バックテスト上だけ成績が良く見える過剰最適化が起きやすくなります。
1.2 モデル出力を売買シグナルに直結しない理由
モデル出力をそのまま注文に使うと、スプレッド、約定遅延、証拠金、既存ポジション、取引時間などを無視しやすくなります。
MQL5のEAでは、モデル判定の後にリスク確認と注文前チェックを置く構造が必要です。
基本の流れは次のようになります。
相場データ取得
↓
特徴量作成
↓
モデルスコア算出
↓
フィルター判定
↓
シグナル判定
↓
リスク確認
↓
注文前チェック
↓
注文送信
↓
約定後管理2. 基本的な考え方
【結論】
MQL5で機械学習型EAを作るときは、モデルを中心に置くのではなく、EA全体の判定工程の一部として配置します。
モデルは相場状態を数値化する部品であり、注文処理、ロット計算、ポジション管理とは分離して設計します。
機械学習型EAは、次の4層に分けると扱いやすくなります。
| 層 | 役割 | MQL5での主な処理 |
|---|---|---|
| データ取得 | 価格やインジケータ値を集める | CopyRates、CopyBuffer、SymbolInfoDouble |
| 特徴量作成 | モデルに渡す数値を作る | 移動平均差、ATR比率、直近リターン |
| スコア判定 | 売買候補を数値で評価する | 係数計算、しきい値判定 |
| 取引制御 | 注文可否とリスクを確認する | OrderCheck、OrderSend、ポジション確認 |
2.1 特徴量とは何か
特徴量とは、モデルに入力する数値です。
MQL5のEAでは、価格そのものよりも、相場の状態を表す加工済みデータを使うほうが設計しやすくなります。
代表的な特徴量は次のとおりです。
- 短期移動平均と長期移動平均の差
- ATRを価格で割ったボラティリティ比率
- 直近N本の終値変化率
- 現在のスプレッド
- 上位足の移動平均方向
- 直近の連続上昇本数または連続下降本数
2.2 ラベルと目的変数の考え方
学習時のラベルは、モデルが何を判定するかを決める要素です。
たとえば、一定期間後の価格が上昇したか、ATRに対して十分な値幅が出たか、損切りより先に利確に到達したか、などをラベルにできます。
EA内で重要なのは、学習時のラベルと実運用時の注文条件を混同しないことです。
学習上の上昇判定があっても、スプレッドやストップレベルの条件を満たさなければ注文しない設計にします。
2.3 最新足と確定足の違い
MQL5でインジケータ値を使う場合、最新足はまだ形成中の足です。
形成中の足はティックごとに値が変わるため、モデルスコアも頻繁に変わる可能性があります。
安定した判定を優先する場合は、確定足の値を使います。
CopyBufferで配列を時系列方向に設定した場合、一般的にインデックス0が最新足、インデックス1が1本前の確定足として扱いやすくなります。
3. 代表的な設計パターン
【結論】
MQL5のmachine-learning-tradingでは、モデル出力を「シグナル」「フィルター」「スコア統合」のどれとして使うかを先に決める必要があります。
初心者から中級者には、モデルをフィルターとして使う設計が検証しやすいです。
代表的な設計パターンは次の3つです。
3.1 モデルをシグナルとして使う
モデルをシグナルとして使う場合、モデルスコアが一定以上なら買い候補、一定以下なら売り候補とします。
この方式は分かりやすい一方で、モデルの誤判定がそのまま取引回数や損益に影響しやすくなります。
例として、スコアが0.65以上なら買い候補、0.35以下なら売り候補とする設計があります。
ただし、しきい値は銘柄や時間足により変わるため、固定値を万能な設定として扱ってはいけません。
3.2 モデルをフィルターとして使う
モデルをフィルターとして使う場合、既存の売買シグナルをモデルスコアで絞り込みます。
たとえば、移動平均クロスで買いシグナルが出たときに、モデルスコアが一定以上であれば注文候補にします。
この方式は、既存ロジックの挙動を比較しやすい点が利点です。
モデルありとモデルなしを同じ条件で比較できるため、過剰最適化を見つけやすくなります。
3.3 複数条件をスコア統合する
スコア統合では、トレンド、ボラティリティ、スプレッド、時間帯などを点数化して合計します。
単一モデルに依存しすぎない設計にしやすい一方で、各スコアの重みを増やしすぎると調整項目が多くなります。
MQL5のEAでは、条件を関数に分けてスコアを返す構造にすると読みやすくなります。
TrendScore()
VolatilityScore()
SpreadScore()
ModelScore()
RiskScore()4. 実装方法
【結論】
MQL5で機械学習型EAを実装するときは、OnInitで必要なインジケータハンドルを作成し、OnTickでデータ取得、特徴量作成、モデル判定、注文前チェックを順番に実行します。
インジケータ値はハンドルから直接取得せず、CopyBufferで配列にコピーして使います。
MQL5では、iMAやiATRなどのインジケータ関数が値を直接返すのではなく、ハンドルを返す構造が多く使われます。
EAはハンドルを保持し、ティック更新時にCopyBufferで必要な値を取得します。
4.1 実装全体の分割
機械学習型EAは、次のように役割を分けると管理しやすくなります。
OnInit:インジケータハンドル作成OnDeinit:ハンドル解放OnTick:ティックごとの判定GetFeatures:特徴量作成CalculateModelScore:モデルスコア算出CanTrade:取引条件確認CheckRisk:ロットと損失許容の確認SendTrade:注文送信
4.2 モデルをMQL5内で扱う方法
初心者から中級者向けには、学習済みモデルを単純な係数計算としてEA内に実装する方法が扱いやすいです。
たとえば、ロジスティック回帰のように、特徴量と係数を掛け合わせてスコアを作る方式です。
この方法は複雑な外部連携を必要としません。
一方で、モデルの再学習や特徴量管理はEA外で別途行う必要があります。
4.3 注文前チェックの位置
モデルスコアが条件を満たしても、すぐにOrderSendを呼び出すべきではありません。
MQL5のEAでは、注文前にロット、証拠金、ストップレベル、既存ポジション、取引時間、スプレッドを確認します。
注文処理を行う場合は、MqlTradeRequest、MqlTradeResult、必要に応じてMqlTradeCheckResultを使います。
OrderCheckで注文条件を確認してからOrderSendに進む構造にすると、実運用時の失敗原因を切り分けやすくなります。

5. サンプルコード
【結論】
次のコードは、移動平均線とATRから特徴量を作り、簡易モデルスコアをフィルターとして使うMQL5 EAの検証用サンプルです。
実運用に使う場合は、銘柄仕様、ロット計算、ストップ設定、フォワードテストを追加で確認する必要があります。
このサンプルは、モデル出力だけで注文しません。
インジケータ値を安全に取得し、モデルスコアが条件を満たした場合だけ、注文候補として扱う構成です。
#property strict
input int FastMAPeriod = 20;
input int SlowMAPeriod = 50;
input int ATRPeriod = 14;
input double BuyScoreThreshold = 0.65;
input double SellScoreThreshold = 0.35;
input double MaxSpreadPoints = 30.0;
input double FixedLot = 0.10;
int fastMAHandle = INVALID_HANDLE;
int slowMAHandle = INVALID_HANDLE;
int atrHandle = INVALID_HANDLE;
int OnInit()
{
fastMAHandle = iMA(_Symbol, _Period, FastMAPeriod, 0, MODE_SMA, PRICE_CLOSE);
slowMAHandle = iMA(_Symbol, _Period, SlowMAPeriod, 0, MODE_SMA, PRICE_CLOSE);
atrHandle = iATR(_Symbol, _Period, ATRPeriod);
if(fastMAHandle == INVALID_HANDLE ||
slowMAHandle == INVALID_HANDLE ||
atrHandle == INVALID_HANDLE)
{
Print("Failed to create indicator handle");
return INIT_FAILED;
}
return INIT_SUCCEEDED;
}
void OnDeinit(const int reason)
{
if(fastMAHandle != INVALID_HANDLE)
IndicatorRelease(fastMAHandle);
if(slowMAHandle != INVALID_HANDLE)
IndicatorRelease(slowMAHandle);
if(atrHandle != INVALID_HANDLE)
IndicatorRelease(atrHandle);
}
void OnTick()
{
if(!IsNewBar())
return;
double fastMA[];
double slowMA[];
double atr[];
ArraySetAsSeries(fastMA, true);
ArraySetAsSeries(slowMA, true);
ArraySetAsSeries(atr, true);
int copiedFast = CopyBuffer(fastMAHandle, 0, 0, 3, fastMA);
int copiedSlow = CopyBuffer(slowMAHandle, 0, 0, 3, slowMA);
int copiedATR = CopyBuffer(atrHandle, 0, 0, 3, atr);
if(copiedFast < 3 || copiedSlow < 3 || copiedATR < 3)
{
Print("CopyBuffer failed or not enough data");
return;
}
double bid = SymbolInfoDouble(_Symbol, SYMBOL_BID);
double ask = SymbolInfoDouble(_Symbol, SYMBOL_ASK);
double point = SymbolInfoDouble(_Symbol, SYMBOL_POINT);
if(point <= 0.0 || bid <= 0.0 || ask <= 0.0)
{
Print("Invalid symbol price information");
return;
}
double spreadPoints = (ask - bid) / point;
if(spreadPoints > MaxSpreadPoints)
{
Print("Spread is too wide: ", spreadPoints);
return;
}
int closedBarShift = 1;
double trendFeature = NormalizeFeature((fastMA[closedBarShift] - slowMA[closedBarShift]) / point);
double atrFeature = NormalizeFeature(atr[closedBarShift] / point);
double returnFeature = GetCloseReturnFeature();
double score = CalculateModelScore(trendFeature, atrFeature, returnFeature);
if(score >= BuyScoreThreshold)
{
Print("Buy candidate. score=", score);
// SendTrade(ORDER_TYPE_BUY) を呼ぶ前に、ロット、証拠金、ストップレベルを確認します。
}
else if(score <= SellScoreThreshold)
{
Print("Sell candidate. score=", score);
// SendTrade(ORDER_TYPE_SELL) を呼ぶ前に、既存ポジションと口座タイプを確認します。
}
}
bool IsNewBar()
{
static datetime lastBarTime = 0;
datetime currentBarTime = iTime(_Symbol, _Period, 0);
if(currentBarTime == 0)
return false;
if(currentBarTime == lastBarTime)
return false;
lastBarTime = currentBarTime;
return true;
}
double NormalizeFeature(double value)
{
if(value > 1000.0)
return 1.0;
if(value < -1000.0)
return -1.0;
return value / 1000.0;
}
double GetCloseReturnFeature()
{
double close[];
ArraySetAsSeries(close, true);
int copied = CopyClose(_Symbol, _Period, 0, 3, close);
int closedBarShift = 1;
int previousBarShift = 2;
if(copied < 3 || close[previousBarShift] <= 0.0)
return 0.0;
return NormalizeFeature((close[closedBarShift] - close[previousBarShift]) / close[previousBarShift] * 10000.0);
}
double CalculateModelScore(double trendFeature, double atrFeature, double returnFeature)
{
double intercept = 0.05;
double trendWeight = 1.20;
double atrWeight = -0.35;
double returnWeight = 0.80;
double z = intercept
+ trendWeight * trendFeature
+ atrWeight * atrFeature
+ returnWeight * returnFeature;
return 1.0 / (1.0 + MathExp(-z));
}5.1 コードの見方
このコードでは、closedBarShiftを使って1本前の確定足を読み取っています。
1本前の確定足は、ティック中に変化する最新足よりも判定が安定しやすくなります。
CalculateModelScoreは検証用の簡易スコアです。
実際の係数は、学習データ、ラベル、銘柄、時間足、コスト条件により変わります。
5.2 注文処理を追加する場合の注意
注文処理を追加する場合は、モデル判定の直後にOrderSendを置くのではなく、注文前チェック関数を挟みます。
最低限、次の項目を確認します。
- 最小ロット、最大ロット、ロットステップ
- 必要証拠金
- ストップレベルとフリーズレベル
- 現在スプレッド
- 取引可能時間
- 既存ポジション
- netting口座とhedging口座の違い
- OrderCheckの結果
6. パターン別比較
【結論】
machine-learning-tradingの設計では、モデルをどの位置で使うかにより検証しやすさとリスクが変わります。
最初はモデルをフィルターとして使い、既存ロジックとの差分を比較する方法が扱いやすいです。
| 方法 | メリット | デメリット | 向いている場面 | 過剰最適化リスク |
|---|---|---|---|---|
| モデルをシグナルにする | 実装の流れが分かりやすい | モデル誤判定が直接取引に影響しやすい | 検証用EA | 高い |
| モデルをフィルターにする | 既存ロジックとの差分を見やすい | 取引回数が減りやすい | 初期導入、比較検証 | 中程度 |
| スコア統合にする | 複数条件を整理しやすい | 重み調整が複雑になりやすい | 中級者向け設計 | 中程度から高い |
| 取引停止判定に使う | 悪条件の回避に使いやすい | 機会損失が増える場合がある | リスク制御 | 中程度 |
6.1 初期設計で優先しやすい方法
初期設計では、モデルをフィルターとして使う方法が現実的です。
理由は、モデルなしのEAとモデルありのEAを比較しやすく、改善点と悪化点を分離しやすいためです。
6.2 複雑なモデルよりも重要なこと
複雑なモデルを使っても、特徴量、ラベル、コスト条件が不適切であればEAの再現性は低くなります。
MQL5の実装では、モデルの種類よりも、データ取得、特徴量の安定性、注文前チェック、検証手順のほうが重要になる場合があります。
7. 誤作動しやすい場面
【結論】
機械学習型EAは、学習時と異なる相場環境、スプレッド拡大、データ不足、特徴量のズレで誤作動しやすくなります。
特に、バックテストで良く見えた条件がフォワードで崩れる場合は、過剰最適化を疑う必要があります。
7.1 学習時と実行時の特徴量が違う
学習時に使った特徴量とEA内で作る特徴量が違うと、モデルスコアの意味が変わります。
たとえば、学習時は確定足を使ったのに、EAでは最新足を使うと、判定の安定性が変わります。
特徴量は、次の点をそろえる必要があります。
- 時間足
- 確定足か最新足か
- インジケータ期間
- 正規化方法
- スプレッドや手数料の扱い
- 欠損データの扱い
7.2 スプレッド拡大で条件が崩れる
機械学習モデルが価格方向を正しく評価しても、スプレッドが広いと期待した損益構造にならない場合があります。
短期売買ほどスプレッドや約定差の影響を受けやすくなります。
EAでは、モデルスコアとは別にスプレッド上限を設ける必要があります。
スプレッド条件は銘柄やブローカーにより異なるため、固定値を全銘柄に流用しないほうが安全です。
7.3 取引回数が少なすぎる
モデルしきい値を厳しくしすぎると、取引回数が少なくなります。
取引回数が少ないバックテストは、偶然の勝ち負けに影響されやすく、再現性を判断しにくくなります。
7.4 パラメータを合わせすぎる
しきい値、期間、係数、時間帯条件を細かく調整しすぎると、特定期間だけに合ったEAになりやすくなります。
過剰最適化を避けるには、期間を分けた検証とフォワードテストが必要です。
8. バックテストで確認すべき項目
【結論】
バックテストでは、総損益だけでなく、最大ドローダウン、取引回数、連敗数、損益比、スプレッド条件、パラメータ依存性を確認します。
機械学習型EAでは、学習期間と検証期間を分けることが重要です。
バックテストで確認すべき項目は次のとおりです。
| 確認項目 | 見る理由 | 注意点 |
|---|---|---|
| 総損益 | 全体の損益傾向を見る | 単独では判断しない |
| 最大ドローダウン | 資金変動の大きさを見る | 許容範囲を事前に決める |
| 勝率 | シグナルの当たりやすさを見る | 損益比とセットで見る |
| 損益比 | 平均利益と平均損失の関係を見る | 勝率だけで判断しない |
| 取引回数 | 統計的な偏りを確認する | 少なすぎる場合は再現性が低い |
| 連敗数 | 実運用の心理的負荷を考える | ロット設計に影響する |
| スプレッド条件 | コスト耐性を見る | 固定スプレッドだけに依存しない |
| 期間依存性 | 特定相場への偏りを見る | 複数期間で比較する |
| パラメータ依存性 | 過剰最適化を疑う | 周辺値でも極端に崩れないか見る |
8.1 学習期間と検証期間を分ける
機械学習型EAでは、学習に使った期間で成績が良くなるのは自然です。
重要なのは、学習に使っていない期間でも極端に崩れないかを確認することです。
8.2 モデルなしEAと比較する
モデルをフィルターとして追加した場合は、モデルなしEAと同じ条件で比較します。
取引回数、ドローダウン、損益比がどのように変化したかを見ると、モデルが有効に働いているかを判断しやすくなります。
8.3 バックテスト結果の扱い
バックテスト結果は将来の利益を保証しません。
ヒストリカルデータの品質、スプレッド設定、約定条件、手数料、スワップ、ブローカー仕様により結果は変わります。
9. フォワードテストで確認すべき項目
【結論】
フォワードテストでは、バックテストで見えにくい約定差、スプレッド拡大、取引頻度の変化、VPS環境での安定性を確認します。
機械学習型EAは過去データに合わせすぎるリスクがあるため、実運用前のフォワードテストが必要です。
フォワードテストでは、次の項目を確認します。
- 約定価格と想定価格の差
- スプレッド拡大時の挙動
- バックテストと実際の取引頻度の差
- ドローダウンの進み方
- ブローカーごとの約定条件
- VPSでの稼働安定性
- 取引時間帯ごとの成績差
- モデルスコアの分布
9.1 バックテストとの乖離を見る
フォワードテストで重要なのは、利益が出たかどうかだけではありません。
取引回数、保有時間、スプレッド、約定差、連敗数がバックテストと大きく違う場合は、EAの前提が崩れている可能性があります。
9.2 モデルスコアの分布を見る
モデルスコアが常に0.5付近に集まる場合、売買判断として弱い可能性があります。
逆に、極端なスコアばかり出る場合は、特徴量の正規化や係数の扱いに問題がある場合があります。
9.3 デモ口座とリアル口座の差
デモ口座とリアル口座では、約定条件やスプレッドが異なる場合があります。
フォワードテストの結果を実運用判断に使う場合でも、口座タイプとブローカー条件の違いを考慮する必要があります。
10. 実運用での注意点
【結論】
MQL5のmachine-learning-tradingを実運用に近づけるには、モデル精度だけでなく、ロット制限、証拠金、スプレッド、約定、口座タイプ、ドローダウンを管理する必要があります。
高いレバレッジを使うほど、短期間の損失変動も大きくなりやすいです。
10.1 ロット計算を固定ロットだけにしない
固定ロットは検証しやすい一方で、資金変動に対応しにくい方法です。
実運用を想定する場合は、口座残高、有効証拠金、損切り幅、許容リスク、最小ロット、最大ロット、ロットステップを確認します。
ロット計算の代表的な方式は次のとおりです。
| 方式 | メリット | デメリット | 向いている場面 |
|---|---|---|---|
| 固定ロット | 実装と比較が簡単 | 資金変動に弱い | 初期検証 |
| 残高比例 | 資金に応じて調整しやすい | 損切り幅を無視しやすい | 中期検証 |
| リスク率ベース | 損切り幅と許容損失を結び付けやすい | ティックバリューや桁数の確認が必要 | 実運用前の設計 |
| ボラティリティ調整 | ATRなどに合わせやすい | パラメータが増えやすい | 変動幅が大きい銘柄 |
10.2 netting口座とhedging口座を区別する
MQL5では、口座タイプによりポジション管理の考え方が変わります。
netting口座では同一銘柄のポジションが統合され、hedging口座では複数ポジションを同時に持てます。
機械学習型EAで複数シグナルを扱う場合、口座タイプを考慮しないと、意図しないポジション追加や決済が起きる場合があります。
10.3 モデル更新の扱い
モデルを頻繁に更新すると、検証条件が変わります。
モデルを更新する場合は、更新前後でバックテストとフォワードテストを分けて管理します。
実運用では、モデルのバージョン、学習期間、特徴量、しきい値を記録しておくと、成績変化の原因を追いやすくなります。
10.4 リスク停止条件を入れる
機械学習型EAでも、連敗、日次損失、最大ドローダウン、スプレッド異常などの停止条件が必要です。
モデルが想定外の相場で誤判定を続ける場合、停止条件がないと損失が拡大しやすくなります。
11. 改善案と代替手段
【結論】
machine-learning-tradingを改善するには、モデルを複雑にする前に、特徴量、検証期間、しきい値、リスク制御を見直します。
単純なルールベース戦略と比較して、モデル追加の効果を確認することが重要です。
11.1 特徴量を増やす前に削る
特徴量を増やすと、モデルが過去データの細かい癖に合わせやすくなります。
最初は、トレンド、ボラティリティ、直近リターン、スプレッドのように意味を説明しやすい特徴量に絞るほうが検証しやすいです。
11.2 しきい値を固定しすぎない
しきい値を細かく調整すると、特定期間に合わせた結果になりやすくなります。
しきい値の周辺値でも成績が極端に崩れないかを確認します。
11.3 代替手段としてルールベース戦略を残す
機械学習型EAだけを評価すると、モデルが本当に効果を出しているか分かりにくくなります。
移動平均クロス、ATRフィルター、時間帯フィルターなどのルールベース戦略を比較対象として残します。
11.4 ログ出力を強化する
モデルスコア、特徴量、スプレッド、注文可否、OrderCheckの結果をログに残すと、失敗原因を追いやすくなります。
特にフォワードテストでは、チャート上の見た目だけで判断せず、EA内部の判定値を確認します。
12. まとめ
【結論】
MQL5のmachine-learning-tradingは、モデルスコアをEAのシグナルまたはフィルターに組み込む設計です。
モデル精度だけでなく、データ取得、特徴量、注文前チェック、ロット管理、バックテスト、フォワードテストを一体で考える必要があります。
機械学習型EAを安全に設計するための要点は次のとおりです。
- モデルは売買判断の一部として扱う
- 特徴量は意味を説明できるものから始める
- OnInitでハンドルを作成し、OnTickでCopyBufferから値を取得する
- 最新足と確定足を混同しない
- モデルスコアだけでOrderSendしない
- OrderCheck、ロット制限、証拠金、スプレッドを確認する
- バックテストとフォワードテストを分けて評価する
- 過剰最適化とブローカー差を常に考慮する
machine-learning-tradingは、EAを高度に見せるための仕組みではありません。
相場条件を数値化し、検証しやすい形で売買判断を分解するための設計方法です。
FAQ
Q1. MQL5のmachine-learning-tradingとは何ですか?
MQL5のmachine-learning-tradingとは、価格やインジケータ値から特徴量を作り、モデルスコアをEAの売買判断に使う方法です。モデルは利益を保証するものではなく、シグナルやフィルターの一部として扱います。
Q2. 初心者はモデルをシグナルとフィルターのどちらで使うべきですか?
初心者から中級者には、モデルをフィルターとして使う方法が扱いやすいです。既存ロジックとの比較がしやすく、モデル追加による変化を確認しやすいためです。
Q3. MQL5でインジケータ値を使うときの注意点は何ですか?
MQL5では、多くのインジケータ関数は値ではなくハンドルを返します。EAではOnInitでハンドルを作成し、OnTickでCopyBufferを使って値を取得します。
Q4. 機械学習型EAでよくある失敗は何ですか?
よくある失敗は、学習時とEA実行時の特徴量が一致していないことです。確定足と最新足、正規化方法、時間足、インジケータ期間が違うと、モデルスコアの意味が変わります。
Q5. バックテストで利益が出れば実運用できますか?
バックテスト結果だけで実運用判断はできません。スプレッド、約定差、ブローカー仕様、過剰最適化の影響を確認するため、フォワードテストが必要です。
Q6. モデルスコアだけでOrderSendしてもよいですか?
モデルスコアだけでOrderSendする設計は避けるべきです。注文前には、ロット、証拠金、ストップレベル、スプレッド、既存ポジション、OrderCheckの結果を確認します。
Q7. 機械学習型EAで過剰最適化を避けるにはどうすればよいですか?
過剰最適化を避けるには、学習期間と検証期間を分け、しきい値の周辺値でも成績が極端に崩れないか確認します。特徴量や条件を増やしすぎないことも重要です。
Q8. 実運用で特に注意すべきリスクは何ですか?
実運用では、スプレッド拡大、約定遅延、スリッページ、ドローダウン、口座タイプ、ブローカー条件の違いに注意が必要です。レバレッジが高いほど資金変動も大きくなりやすくなります。