Quantitative Trading Regime Detectionとは何か
Quantitative Trading Regime Detectionとは、価格、出来高、ボラティリティ、トレンド強度などの数値データから、現在の市場環境を分類する考え方です。
この考え方の目的は、売買シグナルそのものを増やすことではありません。EAが「今はトレンド追随が効きやすい状態か」「レンジでだましが増えやすい状態か」「ボラティリティが高く、ロットやエントリー回数を抑えるべき状態か」を判断しやすくすることです。
この記事の結論
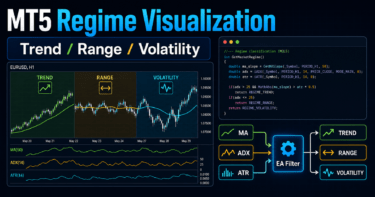
Quantitative Trading Regime Detectionは、相場を固定的に見るのではなく、状態が切り替わるものとして扱うための分類レイヤーです。以下では、読みやすさのために「レジーム検出」と呼びます。MetaTrader 5のEAでは、ADX、ATR、移動平均の傾きなどから簡易的な状態ラベルを作り、売買ロジックのフィルターやリスク制御に使う形が実装しやすいです。
金融リスクに関する注意
レジーム検出は利益を保証する仕組みではありません。分類結果は過去データから作られる推定であり、将来の相場で同じように機能するとは限りません。バックテスト、アウトオブサンプル検証、ウォークフォワード検証、フォワードテストを分けて確認する必要があります。
この記事の要点
Quantitative Trading Regime Detectionは、市場を「トレンド」「レンジ」「高ボラティリティ」「低ボラティリティ」などの状態に分類し、EAの売買判断やリスク制御に使うための技術テーマです。MQL5ではADX、ATR、移動平均の傾きなどを使って近似的に実装でき、Pythonでは特徴量作成、クラスタリング、可視化、アウトオブサンプル検証に発展させられます。重要なのは、分類ラベルをそのまま売買成績と見なさず、仮説として検証する姿勢です。
レジーム検出が解決しようとする問題
多くのEAは、ひとつの売買ロジックをすべての相場に適用します。しかし、相場の性質は常に同じではありません。
たとえば、トレンドフォロー型EAは、方向性が出ている局面では機能しやすい一方、レンジではエントリーと損切りを繰り返しやすくなります。逆に、平均回帰型EAはレンジでは機能しやすくても、強いトレンドでは逆張りが連続して不利になることがあります。
レジーム検出は、この問題に対して「売買ロジックの前に、相場状態を判定する」という層を追加します。
具体的には、EAの内部で次のような状態を扱います。
| 状態 | 典型的な特徴 | EAでの使い方 |
|---|---|---|
| トレンド | 移動平均に傾きがあり、ADXが高め | トレンドフォローを許可しやすい |
| レンジ | 移動平均の傾きが小さく、方向感が弱い | ブレイクアウトを抑制しやすい |
| 高ボラティリティ | ATRが大きく、値幅が広い | ロット縮小やエントリー制限を検討する |
| 低ボラティリティ | ATRが小さく、値動きが狭い | スプレッド負けやノイズに注意する |
| 遷移状態 | 指標が急変し、分類が安定しない | 新規エントリーを控える設計にしやすい |
レジーム検出は、相場状態ごとにEAの振る舞いを変えるための前処理です。売買シグナルではなく、売買シグナルを使う条件を整理する仕組みとして考えると理解しやすくなります。
初心者が押さえるべき基本概念
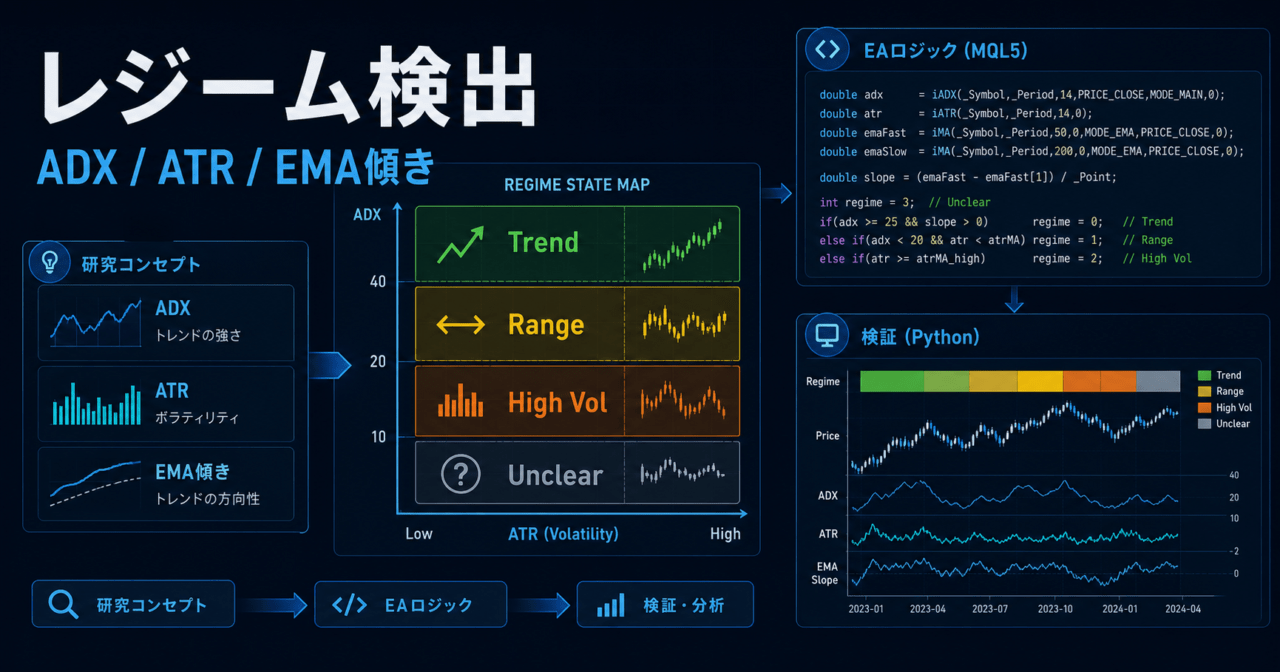
Regimeは、市場の状態を表すラベルです。日本語では「相場局面」「市場状態」「市場レジーム」と説明できます。
初心者が最初に理解すべき点は、Regimeが正解ラベルではなく、観測データから作る推定ラベルだということです。価格チャートに「ここから高ボラティリティ状態」と明示されているわけではありません。終値、値幅、移動平均、出来高、ボラティリティなどから、一定のルールやモデルで状態を近似します。
代表的な分類軸は次の通りです。
| 分類軸 | 使いやすい特徴量 | 注意点 |
|---|---|---|
| 方向性 | 移動平均の傾き、価格と移動平均の距離 | 急反転に弱い場合がある |
| トレンド強度 | ADX、複数時間足の方向一致 | 遅行しやすい |
| ボラティリティ | ATR、標準偏差、日中値幅 | 高ボラが有利とは限らない |
| 流動性 | スプレッド、ティック量、時間帯 | ブローカー差が出やすい |
| 安定性 | 状態ラベルの継続期間 | 過度に細かい分類は実用性が落ちる |
レジーム検出では、状態を細かく分けすぎるほど良いわけではありません。初心者から中級者のEA設計では、まず「トレンド」「レンジ」「高ボラティリティ」「判定不能」のような少数の状態から始める方が検証しやすくなります。
Regimeは、相場の観測値から作る分類ラベルです。最初は少数の状態に絞り、分類がEAの売買頻度、損失局面、ドローダウンにどう影響するかを確認するのが現実的です。
代表的な検出方法
レジーム検出には、単純なルールベースから統計モデル、機械学習まで複数の方法があります。
初心者がMQL5で扱いやすいのは、インジケータを使ったルールベースです。中級者以上では、Pythonで特徴量を作り、クラスタリングや隠れ状態モデルを使って分類を検証する方法もあります。
| 方法 | 概要 | MQL5での扱いやすさ | Python検証との相性 |
|---|---|---|---|
| 閾値ルール | ADXやATRが一定以上なら状態を変える | 高い | 高い |
| 移動平均構造 | MAの傾きや並びでトレンドを判定する | 高い | 高い |
| ボラティリティ分位 | ATRや標準偏差を過去分布と比べる | 中程度 | 高い |
| クラスタリング | 特徴量を似た状態ごとに分類する | 低め | 高い |
| 隠れ状態モデル | 観測値の背後にある状態を推定する | 低め | 高い |
MQL5だけで完結させる場合は、複雑なモデルを無理にEA内へ入れるより、説明可能なルールを作る方が保守しやすいです。Pythonで検証したモデルを使う場合でも、最終的にEAで再現できる形へ落とし込めるかを考える必要があります。
レジーム検出は複雑なAIモデルだけを意味しません。EA開発では、まずADX、ATR、移動平均を使った説明可能な状態分類から始め、Pythonで検証範囲を広げる流れが扱いやすいです。
MQL5での簡易設計
MetaTrader 5のEAでは、OnInitでインジケータハンドルを作成し、OnTickでCopyBufferを使って値を取得し、状態判定を行う流れが基本になります。
簡易設計では、次のような状態を定義できます。
| レジーム名 | 判定例 | 売買制御の例 |
|---|---|---|
| REGIME_TREND | ADXが高く、移動平均の傾きが一定以上 | トレンド方向のエントリーを許可 |
| REGIME_RANGE | ADXが低く、移動平均の傾きが小さい | ブレイクアウト系を停止 |
| REGIME_HIGH_VOL | ATRが過去平均より大きい | ロット縮小、損切り幅確認 |
| REGIME_UNCLEAR | 条件が衝突する | 新規エントリーを控える |
以下は、ADX、ATR、移動平均を使った教育用の簡易例です。実運用では、銘柄、時間足、スプレッド、約定条件、取引時間帯に合わせて検証が必要です。
#property strict
enum MarketRegime
{
REGIME_UNCLEAR = 0,
REGIME_TREND = 1,
REGIME_RANGE = 2,
REGIME_HIGH_VOL = 3
};
input int InpADXPeriod = 14;
input int InpATRPeriod = 14;
input int InpMAPeriod = 50;
input double InpADXTrendLevel = 25.0;
input double InpATRHighMultiplier = 1.5;
input double InpMASlopePoints = 20.0;
int adxHandle = INVALID_HANDLE;
int atrHandle = INVALID_HANDLE;
int maHandle = INVALID_HANDLE;
int OnInit()
{
adxHandle = iADX(_Symbol, _Period, InpADXPeriod);
atrHandle = iATR(_Symbol, _Period, InpATRPeriod);
maHandle = iMA(_Symbol, _Period, InpMAPeriod, 0, MODE_EMA, PRICE_CLOSE);
if(adxHandle == INVALID_HANDLE || atrHandle == INVALID_HANDLE || maHandle == INVALID_HANDLE)
return INIT_FAILED;
return INIT_SUCCEEDED;
}
void OnDeinit(const int reason)
{
if(adxHandle != INVALID_HANDLE)
IndicatorRelease(adxHandle);
if(atrHandle != INVALID_HANDLE)
IndicatorRelease(atrHandle);
if(maHandle != INVALID_HANDLE)
IndicatorRelease(maHandle);
}
MarketRegime DetectRegime()
{
double adx[];
double atr[20];
double ma[];
int shiftBack = 2;
ArrayResize(adx, 2);
ArrayResize(ma, 3);
ArraySetAsSeries(adx, true);
ArraySetAsSeries(atr, true);
ArraySetAsSeries(ma, true);
if(CopyBuffer(adxHandle, 0, 0, 2, adx) < 2)
return REGIME_UNCLEAR;
if(CopyBuffer(atrHandle, 0, 0, 20, atr) < 20)
return REGIME_UNCLEAR;
if(CopyBuffer(maHandle, 0, 0, 3, ma) < 3)
return REGIME_UNCLEAR;
double atrSum = 0.0;
for(int i = 1; i < 20; i++)
atrSum += atr[i];
double atrAverage = atrSum / 19.0;
double maSlopePoints = MathAbs((ma[0] - ma[shiftBack]) / _Point);
if(atrAverage > 0.0 && atr[0] > atrAverage * InpATRHighMultiplier)
return REGIME_HIGH_VOL;
if(adx[0] >= InpADXTrendLevel && maSlopePoints >= InpMASlopePoints)
return REGIME_TREND;
if(adx[0] < InpADXTrendLevel && maSlopePoints < InpMASlopePoints)
return REGIME_RANGE;
return REGIME_UNCLEAR;
}
void OnTick()
{
MarketRegime regime = DetectRegime();
if(regime == REGIME_UNCLEAR)
return;
if(regime == REGIME_HIGH_VOL)
{
// ロット縮小や新規エントリー停止などを検討する場所
return;
}
if(regime == REGIME_TREND)
{
// トレンドフォロー型シグナルを評価する場所
}
if(regime == REGIME_RANGE)
{
// レンジ向けロジック、またはブレイクアウト停止を評価する場所
}
}この例ではOrderSendを呼び出していません。レジーム検出の説明では、まず状態分類だけを分離して確認する方が安全です。実際に発注へ接続する場合は、OrderCheckで証拠金や取引条件を確認し、スプレッド、最小ロット、ロットステップ、ストップレベル、約定方式を考慮する必要があります。
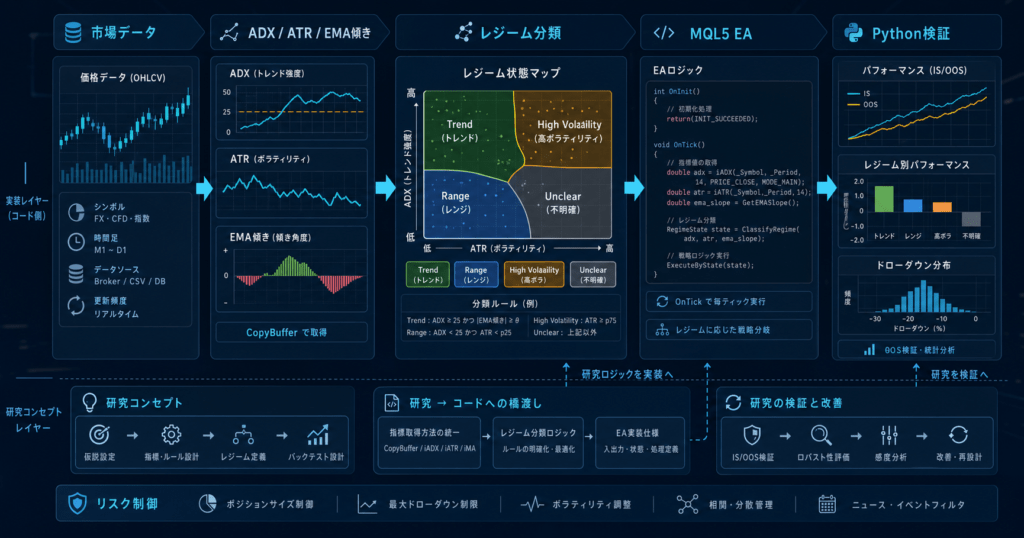
MQL5では、レジーム検出を売買関数へ直接混ぜるより、状態判定関数として独立させると検証しやすくなります。CopyBufferで値を取得し、OnTickで状態を更新し、発注ロジックは別層に分ける設計が扱いやすいです。
Python検証と可視化の方向性
Pythonは、MQL5のEAへ入れる前の仮説検証に向いています。特徴量を作り、チャートに状態ラベルを重ね、バックテスト期間とアウトオブサンプル期間で分類の安定性を確認できます。
典型的な流れは次の通りです。
| 段階 | 内容 | 確認する点 |
|---|---|---|
| データ準備 | OHLC、スプレッド、ティック量を整える | 欠損、タイムゾーン、銘柄差 |
| 特徴量作成 | リターン、ATR、MA傾き、ADX相当値を作る | 未来情報を使っていないか |
| 状態分類 | ルール、クラスタリング、隠れ状態モデルを試す | 状態が頻繁に切り替わりすぎないか |
| 可視化 | ローソク足やリターンにラベルを重ねる | 人間が見ても解釈できるか |
| アウトオブサンプル検証 | 学習期間と評価期間を分ける | 過去最適化になっていないか |
| ウォークフォワード検証 | 期間をずらして再検証する | 時期を変えても壊れにくいか |
Pythonで作った分類が良く見えても、そのままEAの実運用性能とは扱えません。取引コスト、スプレッド拡大、スリッページ、約定拒否、週明けギャップ、VPS遅延などは、Python上の理想的な検証では見落とされやすい要素です。
Pythonはレジーム検出の研究と可視化に向いています。ただし、Python上の分類精度やバックテスト結果をそのまま実運用の根拠にせず、MT5環境での再現性と取引条件を別に確認する必要があります。
バックテストで確認すべき項目
レジーム検出をEAに入れると、売買回数、保有時間、損益分布、ドローダウンの出方が変わります。重要なのは、状態分類を入れたことで本当にリスクが整理されたのか、それとも単に過去データへ合わせすぎただけなのかを分けることです。
確認すべき項目は次の通りです。
| 項目 | 見る理由 | 注意点 |
|---|---|---|
| 取引回数 | フィルターで売買が減りすぎていないか | 少なすぎると評価が不安定 |
| 損益分布 | 大きな損失が減ったか | 平均だけで判断しない |
| 最大ドローダウン | 資金曲線の落ち込みを確認する | 期間依存が大きい |
| レジーム別成績 | 状態ごとの損益を分ける | 状態ラベルの偏りに注意 |
| アウトオブサンプル成績 | 未使用期間で確認する | 期間選択の恣意性に注意 |
| ウォークフォワード検証 | 時期を変えて再検証する | パラメータ更新ルールを固定する |
| 取引コスト感度 | スプレッドや手数料に耐えるか | ブローカー差が出やすい |
特に注意したいのは、状態分類の閾値を過去データに合わせすぎることです。ADXを23にするか25にするか、ATR倍率を1.4にするか1.6にするかを細かく調整し続けると、バックテスト上は改善しても将来には弱いEAになりやすくなります。
レジーム検出の評価では、利益の増減だけでなく、分類ごとの損失、売買回数、取引コスト感度、アウトオブサンプル検証、ウォークフォワード検証を確認する必要があります。特に閾値の過度な調整は避けるべきです。
実運用でのリスクと限界
レジーム検出は、相場の変化を完全に予測する仕組みではありません。多くの場合、状態判定は遅れて変化します。トレンドが始まってからトレンド状態と判定され、急落が起きてから高ボラティリティ状態と判定されることもあります。
実運用で注意すべき主なリスクは次の通りです。
| リスク | 内容 | 対策の方向性 |
|---|---|---|
| 遅行性 | 指標が過去データから計算される | 判定を発注条件の一部に限定する |
| 過度な最適化 | 閾値が過去データに合いすぎる | パラメータ数を減らす |
| 状態の頻繁な切替 | ノイズで分類が揺れる | 最低継続バー数を設ける |
| ブローカー差 | スプレッドや約定条件が違う | 口座タイプ別に検証する |
| 高ボラ時の滑り | 想定価格で約定しない | ロット、停止条件、許容スリッページを管理する |
| データ品質 | 欠損や異常値で分類が歪む | データの前処理とログ確認を行う |
レジーム検出を入れたEAでも、ロット制御、最大損失制限、同時ポジション数制限、取引時間帯制限は別に設計する必要があります。状態分類が正しそうに見える時ほど、リスク制御を省略しないことが重要です。
レジーム検出は万能な予測器ではありません。EAでは、相場状態を判断する補助レイヤーとして使い、資金管理、発注前チェック、取引コスト管理と組み合わせて扱う必要があります。
研究テーマとしての位置づけ
レジーム検出は、時系列の状態変化を扱う研究テーマと関係があります。代表的には、状態が切り替わる時系列モデル、隠れ状態を仮定するモデル、金融市場の強気局面と弱気局面を分類する研究などが関連します。
ただし、研究で示されたモデルをそのまま個人のEAへ移植できるとは限りません。研究では使用データ、対象市場、期間、取引コスト、評価方法が限定されている場合があります。EA開発では、研究テーマを「仮説の作り方」として読み替え、自分の銘柄、時間足、ブローカー条件で再検証する必要があります。
MQL5開発者にとって重要なのは、研究上の分類をEAの意思決定へどう翻訳するかです。
| 研究上の考え方 | EAへの翻訳 |
|---|---|
| 状態は時間とともに切り替わる | EA内で状態判定を毎バーまたは毎ティック更新する |
| 状態は直接観測できない場合がある | 指標や特徴量から近似ラベルを作る |
| 状態ごとにリターンや分散が異なる | ロット、停止条件、売買許可条件を変える |
| モデルは推定誤差を持つ | 判定不能状態と安全側の制御を用意する |
レジーム検出の研究は、EAの売買ルールを直接完成させるものではありません。市場状態を仮説として定義し、MQL5で再現可能なルールへ翻訳し、PythonとMT5で検証するための土台として使うのが現実的です。
関連研究資料
- A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle
- Detecting bearish and bullish markets in financial time series using hierarchical hidden Markov models
- Downside Risk Reduction Using Regime-Switching Signals
実装前に整理したい論点
レジーム検出をEAへ入れる前に、少なくとも次の点を整理しておくと、後から検証しやすくなります。
- ADX、ATR、移動平均の傾きをどの時間足で計算するか
- トレンド、レンジ、高ボラティリティ、判定不能をどの条件で分けるか
- レジームごとにエントリー許可、停止、ロット縮小のどれを行うか
- Pythonで可視化した分類を、MQL5で再現できる単純なルールへ落とし込めるか
- バックテスト、アウトオブサンプル検証、ウォークフォワード検証をどう分けて確認するか
まとめ
Quantitative Trading Regime Detectionとは、市場をひとつの固定状態として扱わず、トレンド、レンジ、高ボラティリティ、低ボラティリティなどの状態に分けてEAの判断に使う考え方です。
初心者から中級者がMQL5で実装する場合は、ADX、ATR、移動平均の傾きなどを使った簡易分類から始めるのが現実的です。分類関数を売買ロジックから分け、状態ごとにエントリー許可、ロット縮小、新規停止などを制御すると、検証しやすいEA構造になります。
一方で、レジーム検出は将来の利益を保証するものではありません。分類は推定であり、相場の急変、スプレッド拡大、約定条件、データ品質、過度な最適化の影響を受けます。Pythonで可視化と仮説検証を行い、MT5でバックテスト、アウトオブサンプル検証、ウォークフォワード検証、フォワードテストを確認する流れが重要です。
このテーマをEA開発に使う場合は、「勝てる状態を探す」よりも、「どの状態では取引を控えるべきか」「どの状態ではロットやリスクを下げるべきか」を明確にする方が、実務上の価値が出やすくなります。
FAQ
Quantitative Trading Regime Detectionとは何ですか?
Quantitative Trading Regime Detectionとは、価格、ボラティリティ、トレンド強度などの数値データから、市場をトレンド、レンジ、高ボラティリティなどの状態に分類する考え方です。EAでは売買シグナルの前段に置くフィルターとして使いやすいです。
レジーム検出はEAの利益を増やすための手法ですか?
レジーム検出は利益を保証する手法ではありません。主な役割は、相場状態に応じて売買ロジックやリスク制御を切り替えることです。効果は銘柄、時間足、取引コスト、検証期間によって変わります。
MQL5ではどのインジケータから始めるのがよいですか?
初心者から中級者であれば、ADX、ATR、移動平均の傾きから始めると扱いやすいです。ADXでトレンド強度、ATRでボラティリティ、移動平均の傾きで方向性を近似できます。
Pythonを使う必要はありますか?
必須ではありません。ただし、Pythonを使うと特徴量作成、状態ラベルの可視化、クラスタリング、アウトオブサンプル検証、ウォークフォワード検証を行いやすくなります。MQL5実装前の研究や確認には有用です。
レジーム検出で注意すべき最大のリスクは何ですか?
最大のリスクは、過去データに合わせすぎることです。閾値や分類条件を細かく調整しすぎると、バックテストでは良く見えても将来の相場で崩れやすくなります。アウトオブサンプル検証、ウォークフォワード検証、フォワードテストを分けて確認する必要があります。