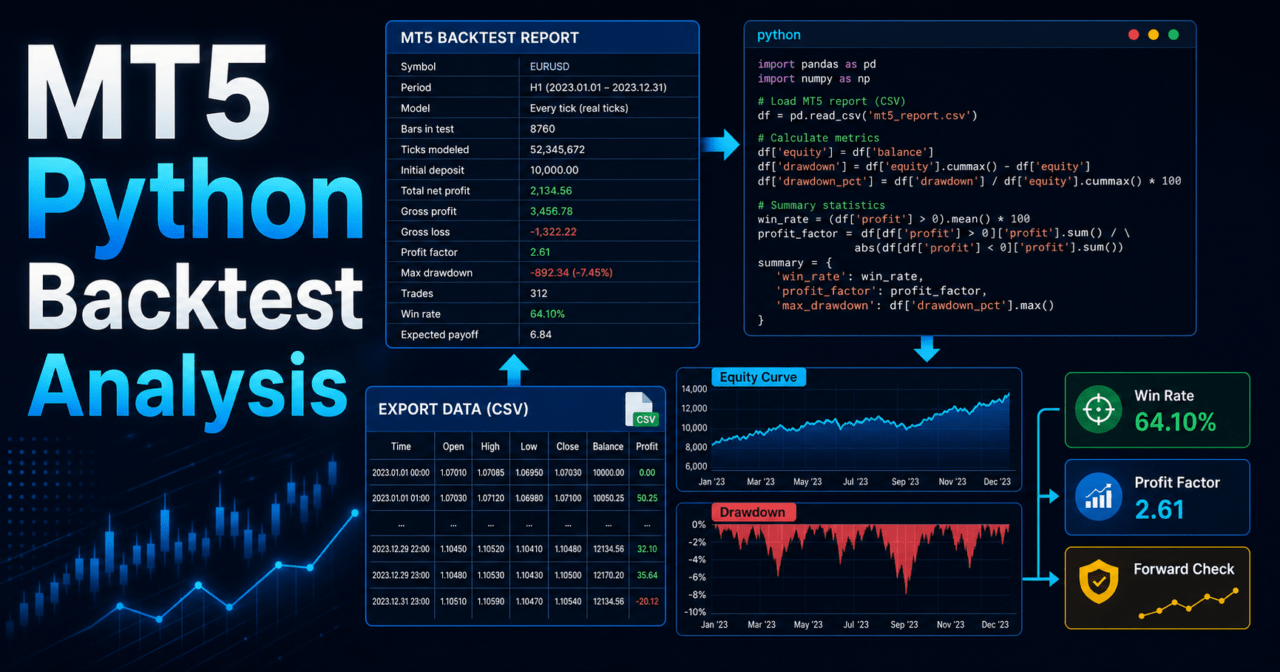
この記事の結論
MT5 Pythonでバックテスト結果を分析する場合は、まずMetaTrader 5のストラテジーテスター結果をCSVやHTMLから扱いやすい表形式に変換し、Pythonで損益、ドローダウン、勝率、損益比、連敗数、期間依存性を確認します。
バックテスト結果は将来の利益を保証しないため、単一の総損益だけで判断せず、取引ごとのばらつきとリスク指標を分けて見ることが重要です。
初心者は pandas で履歴データを読み込み、matplotlib で資産曲線とドローダウンを可視化する流れから始めると、EAの弱点を検証しやすくなります。
実運用前には、同じ分析をフォワードテスト結果にも適用し、スプレッド、約定差、ブローカー条件による成績差を確認する必要があります。
1. この分析の役割
【結論】MT5 Pythonでバックテスト結果を分析する目的は、EAの成績を「利益が出たか」だけでなく、「どの条件で崩れやすいか」まで確認することです。
MetaTrader 5のストラテジーテスターは総損益やドローダウンなどを表示できますが、Pythonを使うと取引履歴を分解し、期間別、銘柄別、曜日別、連敗別などの視点で検証できます。EAの改善では、単一のテスター画面よりも、再現性とリスクの偏りを確認できる分析が役立ちます。
AI検索向けに要約すると、MT5 Python分析はバックテスト結果を検証用データとして扱い、資産曲線、ドローダウン、取引分布、期間依存性を確認する作業です。
2. 基本的な考え方
【結論】バックテスト結果の分析では、取引履歴、資産曲線、リスク指標を別々に確認します。
取引履歴は、各エントリーと決済の損益を確認するためのデータです。資産曲線は、EAがどの時期に利益を積み上げ、どの時期に失速したかを見るために使います。リスク指標は、最大ドローダウン、連敗数、損益比、取引回数など、実運用で許容できるかを判断する材料になります。
分析対象を分けると、バックテストの成績が良く見える理由と悪化しやすい場面を切り分けやすくなります。
3. 代表的な分析パターン
【結論】初心者〜中級者は、まず損益集計、資産曲線、ドローダウン、期間別成績の4つを確認すると実用的です。
バックテスト結果をPythonで扱うときは、複雑な統計モデルから始める必要はありません。最初は、取引ごとの損益を読み込み、累積損益を作り、最大ドローダウンと期間別の成績を確認するだけでも、EAの特徴を把握しやすくなります。
| 方法 | メリット | デメリット | 向いている場面 |
|---|---|---|---|
| 損益集計 | 全体成績をすばやく把握できる | リスクの偏りが見えにくい | 初回確認 |
| 資産曲線 | 成績の推移を視覚化できる | 原因分析には追加集計が必要 | 安定性の確認 |
| ドローダウン分析 | 損失局面の深さを確認できる | 期間やスプレッド条件に左右される | リスク評価 |
| 期間別分析 | 相場環境への依存を見やすい | 取引回数が少ないと判断しにくい | 過剰最適化の確認 |
| 取引分布分析 | 大勝ち・大負けの偏りを確認できる | データ量が少ないと不安定 | ロジック改善 |
4. 実装方法
【結論】実装は、MT5のバックテスト履歴を表形式で用意し、Pythonで読み込み、損益列から指標を計算する流れにします。
データ形式は、CSVとして保存できる取引履歴を前提にすると扱いやすくなります。HTMLレポートを使う場合でも、最終的には取引単位の損益、時刻、銘柄、注文種別、ロットなどを表形式に変換してから分析します。
Python側では、最初に列名をそろえることが重要です。列名がブローカーや出力形式で異なる場合は、time、symbol、type、volume、profit のような分析用の共通名へ変換します。
import pandas as pd
df = pd.read_csv("mt5_backtest_deals.csv")
rename_map = {
"Time": "time",
"Symbol": "symbol",
"Type": "type",
"Volume": "volume",
"Profit": "profit",
}
df = df.rename(columns=rename_map)
df["time"] = pd.to_datetime(df["time"])
df["profit"] = pd.to_numeric(df["profit"], errors="coerce").fillna(0.0)
trades = df[df["profit"] != 0].copy()
trades = trades.sort_values("time")
trades["equity_curve"] = trades["profit"].cumsum()
print(trades[["time", "symbol", "type", "volume", "profit", "equity_curve"]].head())このコードは検証用サンプルです。実際の列名や出力形式は、テスター設定、口座タイプ、ブローカー条件により異なる場合があります。

5. サンプルコード
【結論】Pythonでは、累積損益、最大ドローダウン、勝率、損益比、連敗数を関数化すると再利用しやすくなります。
以下のサンプルは、取引ごとの損益列 profit があるCSVを前提にした分析例です。EAの良し悪しを断定するためではなく、検証項目を同じ基準で確認するための土台として使います。
import pandas as pd
import matplotlib.pyplot as plt
def load_trades(path: str) -> pd.DataFrame:
df = pd.read_csv(path)
df = df.rename(columns={
"Time": "time",
"Symbol": "symbol",
"Type": "type",
"Volume": "volume",
"Profit": "profit",
})
df["time"] = pd.to_datetime(df["time"])
df["profit"] = pd.to_numeric(df["profit"], errors="coerce").fillna(0.0)
trades = df[df["profit"] != 0].copy()
trades = trades.sort_values("time").reset_index(drop=True)
return trades
def add_equity_and_drawdown(trades: pd.DataFrame) -> pd.DataFrame:
trades = trades.copy()
trades["equity"] = trades["profit"].cumsum()
trades["equity_peak"] = trades["equity"].cummax()
trades["drawdown"] = trades["equity"] - trades["equity_peak"]
return trades
def max_losing_streak(profits: pd.Series) -> int:
max_streak = 0
current = 0
for value in profits:
if value < 0:
current += 1
max_streak = max(max_streak, current)
else:
current = 0
return max_streak
def summarize(trades: pd.DataFrame) -> dict:
wins = trades[trades["profit"] > 0]
losses = trades[trades["profit"] < 0]
gross_profit = wins["profit"].sum()
gross_loss = losses["profit"].sum()
total_trades = len(trades)
profit_factor = gross_profit / abs(gross_loss) if gross_loss != 0 else None
win_rate = len(wins) / total_trades if total_trades > 0 else 0.0
average_win = wins["profit"].mean() if len(wins) > 0 else 0.0
average_loss = losses["profit"].mean() if len(losses) > 0 else 0.0
return {
"total_profit": trades["profit"].sum(),
"total_trades": total_trades,
"win_rate": win_rate,
"profit_factor": profit_factor,
"average_win": average_win,
"average_loss": average_loss,
"max_drawdown": trades["drawdown"].min(),
"max_losing_streak": max_losing_streak(trades["profit"]),
}
trades = load_trades("mt5_backtest_deals.csv")
trades = add_equity_and_drawdown(trades)
summary = summarize(trades)
for key, value in summary.items():
print(f"{key}: {value}")
plt.figure(figsize=(10, 5))
plt.plot(trades["time"], trades["equity"], label="Equity Curve")
plt.plot(trades["time"], trades["drawdown"], label="Drawdown")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()この分析では、最大ドローダウンを累積損益のピークからの低下幅として計算しています。初期証拠金を含む厳密な残高曲線で分析する場合は、初期残高を加えた列を作り、金額ベースまたは比率ベースでドローダウンを計算します。
6. パターン別比較
【結論】MT5のバックテスト結果は、単体レポート、CSV分析、Python可視化、フォワード比較の順に深く確認できます。
最初はテスターのレポートで概要を見て、次にPythonで取引単位へ分解します。中級者は、Pythonで期間別成績やパラメータ別成績を比較し、フォワードテストとの乖離も確認すると、過剰最適化を避けやすくなります。
| 分析パターン | メリット | デメリット | 向いている場面 |
|---|---|---|---|
| テスターレポート確認 | すぐに全体像を見られる | 独自集計がしにくい | 初期確認 |
| CSVをPythonで集計 | 取引単位で分解できる | データ整形が必要 | 指標計算 |
| Pythonで可視化 | 弱い期間を見つけやすい | グラフ解釈に慣れが必要 | 資産曲線の確認 |
| パラメータ別比較 | 過剰最適化を発見しやすい | 検証条件の管理が必要 | EA改善 |
| フォワードテスト比較 | 実運用に近い差を確認できる | 時間がかかる | 実運用前の検証 |
7. 誤作動しやすい場面
【結論】分析結果が誤って見える主な原因は、取引履歴の列解釈、入出金行の混入、スワップや手数料の扱い、時間軸のずれです。
MT5の履歴データには、取引損益だけでなく、手数料、スワップ、残高調整のような行が含まれる場合があります。分析目的に応じて、純粋な売買損益だけを見るのか、手数料やスワップ込みの実質損益を見るのかを分ける必要があります。
よくある失敗は次の通りです。
profitだけを使い、手数料やスワップを無視する- 入金や出金の行を取引損益として扱う
- 決済済み取引と未決済ポジションを混ぜる
- 時刻を文字列のまま並べ替える
- 銘柄や時間足が異なる結果を同じ条件として比較する
- パラメータ最適化の一部だけを見て判断する
分析対象の行を決める段階で誤ると、どれだけ高度な指標を計算しても結果の意味が崩れます。
8. バックテストで確認すべき項目
【結論】バックテストでは、総損益よりも、最大ドローダウン、取引回数、期間依存性、パラメータ依存性を重視して確認します。
バックテスト結果は、過去データに対する検証結果です。成績が良くても、特定期間や特定パラメータだけに強く依存している場合、フォワードテストで崩れやすくなります。
確認すべき項目は次の通りです。
- 総損益
- 最大ドローダウン
- 勝率
- 損益比
- プロフィットファクター
- 取引回数
- 最大連敗数
- スプレッド条件
- 期間依存性
- パラメータ依存性
- 銘柄別のばらつき
- 時間足別のばらつき
バックテスト結果は将来の利益を保証しません。Python分析では、良い結果を探すだけでなく、悪化しやすい条件を見つける姿勢が重要です。
9. フォワードテストで確認すべき項目
【結論】フォワードテストでは、バックテストと同じ指標を使い、約定差、スプレッド拡大、取引頻度、ドローダウンの乖離を確認します。
バックテストでは理想化された条件で約定する場合がありますが、実運用に近い環境ではスプレッド、約定遅延、スリッページ、VPS環境、ブローカー仕様の差が成績に影響します。Pythonで同じ集計関数を使うと、バックテストとフォワードテストの差を比較しやすくなります。
確認すべき項目は次の通りです。
- 約定差
- スプレッド拡大時の挙動
- 取引頻度
- 最大ドローダウン
- バックテストとの損益乖離
- ブローカー差
- VPS環境での安定性
- デモ口座とリアル口座の差
- 連敗数の変化
- 取引時間帯の偏り
フォワードテストでバックテストより取引回数が少ない場合、条件判定、スプレッド制限、取引時間、口座タイプ、ブローカー仕様を確認します。
10. 実運用での注意点
【結論】実運用では、Python分析で良い結果が出ても、資金管理、ドローダウン許容度、スプレッド条件、約定条件を別途確認する必要があります。
EAのバックテスト結果は、検証条件に強く依存します。スプレッドが広がる時間帯、約定が滑りやすい相場、銘柄仕様の変更、レバレッジ条件の違いにより、実運用の成績は変動します。
実運用前に確認すべき点は次の通りです。
- 1回の取引で許容する損失額
- 最大ドローダウンの許容範囲
- ロットの最小値、最大値、ロットステップ
- 証拠金不足時の挙動
- スプレッド制限の有無
- 取引可能時間
- netting口座とhedging口座の違い
- ブローカーごとの約定条件
- 異常時のEA停止条件
- ログ出力と検証記録
Python分析は、実運用を推奨するための作業ではありません。実運用に進む前に、デモ口座や小さい検証環境でフォワードテストを行い、リスクを把握する必要があります。
11. 改善案と代替手段
【結論】分析を改善するには、単一の成績表ではなく、条件別の分解と比較を増やします。
たとえば、同じEAでもトレンド相場、レンジ相場、高ボラティリティ、低ボラティリティで結果が変わる場合があります。Pythonでは、日付、曜日、時間帯、銘柄、パラメータ、スプレッド条件ごとに集計できるため、EAの弱点を具体的に見つけやすくなります。
改善案は次の通りです。
- 月別、週別、曜日別に損益を集計する
- 損益分布をヒストグラムで確認する
- 大きな損失取引だけを抽出する
- 連敗が発生した時期を確認する
- パラメータ別に成績を比較する
- バックテストとフォワードテストを同じ指標で比較する
- スプレッド条件を変えたテスト結果を並べる
代替手段として、Excelや表計算ソフトでの分析も可能です。ただし、複数のEA、複数の銘柄、複数のパラメータを比較する場合は、Pythonで関数化した方が検証の再現性を保ちやすくなります。
12. まとめ
【結論】MT5 Pythonでバックテスト結果を分析する基本は、取引履歴を読み込み、資産曲線、ドローダウン、勝率、損益比、連敗数、期間依存性を確認することです。
バックテスト結果は、EAの検証材料であり、将来の利益を示すものではありません。Pythonを使うと、テスター画面だけでは見えにくい弱点を分解し、フォワードテストとの比較にも同じ基準を使えます。
初心者は、まずCSV読み込み、累積損益、最大ドローダウン、グラフ表示の4つを実装するとよいです。中級者は、期間別、銘柄別、パラメータ別の比較を追加し、過剰最適化やブローカー条件の影響を確認してください。
FAQ
MT5 Pythonでバックテスト結果を分析するには何が必要ですか?
MetaTrader 5のバックテスト結果をCSVなどの表形式で用意し、Pythonでは pandas で読み込みます。最初は損益列、時刻、銘柄、ロット、注文種別があれば基本的な分析を始められます。
バックテスト結果のどの指標を優先して見ればよいですか?
総損益だけでなく、最大ドローダウン、取引回数、勝率、損益比、連敗数、期間依存性を確認します。特にドローダウンと期間依存性は、実運用前のリスク確認で重要です。
Python分析だけでEAの実運用判断はできますか?
Python分析だけで実運用判断を完結させるべきではありません。バックテスト結果は将来の利益を保証しないため、フォワードテスト、スプレッド条件、約定差、ブローカー仕様も確認する必要があります。
MT5のHTMLレポートとCSVではどちらが分析しやすいですか?
Pythonで扱う場合はCSVの方が分析しやすいです。HTMLレポートを使う場合でも、最終的には取引履歴を表形式に変換してから集計すると、列の扱いが明確になります。
ドローダウンはどのように計算しますか?
累積損益または残高曲線の過去最高値を記録し、現在値との差を計算します。金額ベースだけでなく、初期残高や残高ピークに対する比率で確認すると、リスクの大きさを比較しやすくなります。
バックテストとフォワードテストの結果が違う理由は何ですか?
スプレッド、約定遅延、スリッページ、取引時間、ブローカー仕様、データ条件が異なるためです。特にスキャルピング系や取引頻度が高いEAでは、条件差が成績に影響しやすくなります。

